
How Cake uses Kinesis to deliver real-time insights.
Cake brings together all your existing bank accounts and transactions. The app analyses your financial data and habits, to make your life better. Cake makes your bank accounts pay off again, by sharing its profits with you. It’s the app that rewrites the rules. To make sure you will always get your piece.
What is Kinesis?
Amazon Kinesis is a managed, easily scalable and durable real-time data streaming service. Amazon Kinesis allows real-time processing of streaming data.
It is designed for real-time applications and allows developers to take in virtually any amount of data from several sources as it is able to capture gigabytes of data per second from hundreds of thousands of sources. All of this while still maintaining compliance needs by encrypting sensitive data and allowing strict security policies of what applications can read from these streams.
Cake's Application Flow
When a new user signs up to the app, or when new transactions come in, Cake needs to enrich the data almost instantaneously. To achieve this, Cake leverages Amazon Kinesis for stream processing. The technology allows Cake to ingest, buffer and process financial data in real-time, without having to manage any streaming infrastructure.
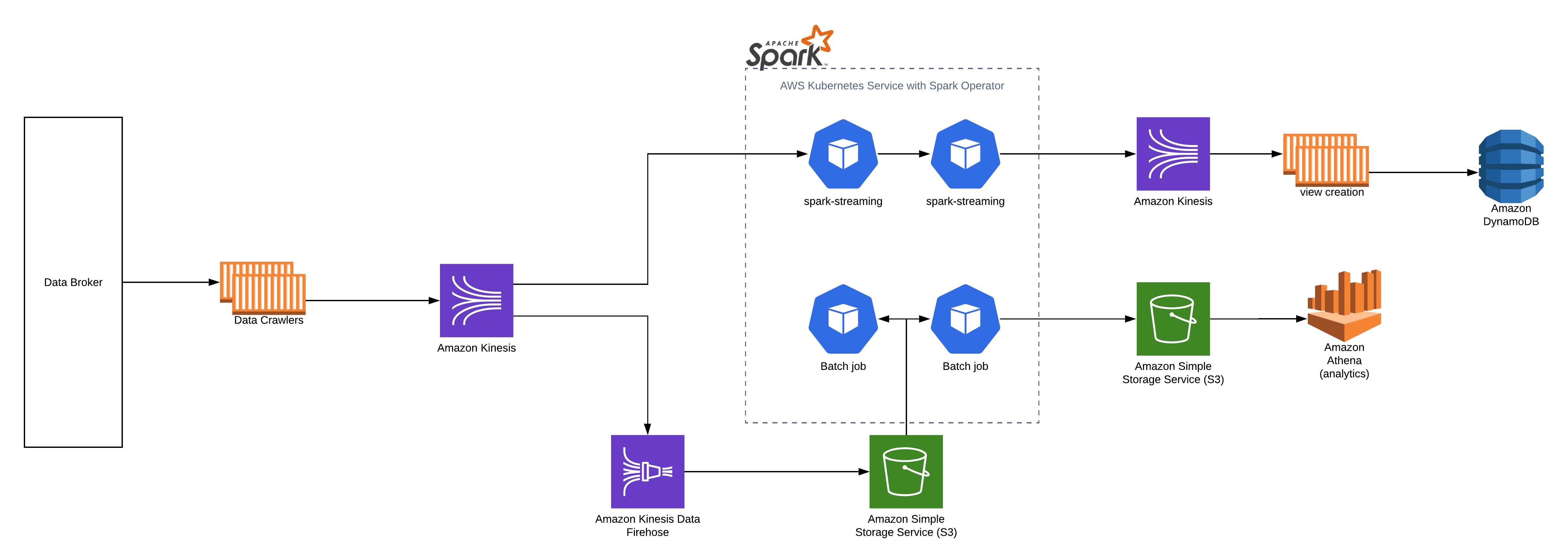
Cake’s usage of kinesis solves two use-cases:
- Machine Learning models need to run immediately when the data is available
- Ingested data needs to be transformed and stored in a format to run analytics on it
Data is ingested through an API provided by a data broker. A crawler retrieves new data from the data broker API endpoint and puts it on the kinesis stream. From there the data will be available to other backend processes reading from the stream (if they have the permissions to do so). To keep a raw copy of the data, Kinesis Firehose is used to store the data in S3. This enables the ability to replay events in a disaster recovery event. At the same time, Spark Streaming jobs within a Kubernetes cluster (AWS EKS) will receive the data and will start running the machine learning models on it. The results go to another kinesis stream where backend processes can pick up these results and populate a view in dynamodb. After this step, the data can be displayed to the user quickly and easily.
Event processing happens on a micro-batch of data and is designed to quickly run inferences and get the data in the correct datastore. To create the analytics dataset, we need another approach. The full dataset needs to be loaded, transformed and enriched with other data sources. To achieve this we can use the data stored in S3 by Kinesis Firehose. Batch jobs can periodically process all data, enrich it, and put it in the parquet file format for Amazon Athena and other Business Intelligence Software to query.
Benefits
For Cake the major benefit is not to have to manage streaming infrastructure. When event data exceeds the kinesis shard limits, scaling out happens easily without having to make any code changes. Extra shards are added and an extra backend worker can start processing the extra shard.
Data security is handled by AWS KMS, allowing to transparently encrypt & decrypt streaming data. AWS Kinesis also nicely integrates with the existing Identity & Access Management infrastructure (IAM) that AWS provides, ensuring authentication and authorization controls.
Finally, one sometimes overlooked benefit is that Amazon Kinesis integrates with other AWS products. For example, Kinesis can easily store all the data passed through its stream in S3, by also sending the data to Amazon Kinesis Data Firehose.